
计算机用二进制编码来表示字符。二进制编码的类型不只有一种,常用的有 UTF-8、GB2312、GB18030、Windows 1252 等等。不同的编码类型采用不同的编码格式,很多编码类型是不兼容的。同一段二进制编码数据,如果使用错误的编码类型读取时,就可能显示成错误的字符,这也就是乱码的根源。
字符读取
字符读取是采用指定的编码类型将二进制编码数据读取为字符。比如二进制数据“C3 8C C3 86”,使用 UTF-8 编码类型读取时表示为字符“唐”。
字符读取是只读的,不会改变原本的二进制数据。
简单的乱码
仅仅只是读取数据时采用了错误的编码类型,是一种最简单的情况。这种情况只要切换到正确的编码类型后再进行读取就可以了。
我们常见的乱码会比较复杂,通常是使用错误的编码类型读取数据后,又进行了编码转换。
编码转换
编码转换是使用不同的编码类型来表示相同的字符。比如“唐”的 UTF-8 编码是“E5 94 90”,转换为 GB18030 编码后变为“CC C6”,但是仍然表示“唐”。
复杂情况的分析
下面举个例子描述比较复杂的情况:
-
一个 GB18030 编码的字符“唐”的二进制数据是“CC C6”;
-
使用 Windows 1252 编码类型来读取时,显示的字符不是“唐”,是“ÌÆ”;
-
将“ÌÆ”转换成 UTF-8 编码,二进制数据变成了“C3 8C C3 86”。
这个时候,我们再使用任何编码类型都无法正确读出“唐”这个字符。因为数据本身已经错了,怎么读也不可能得到原本的信息。换句话说,“C3 8C C3 86”这个二进制数据在任何编码类型中都对应不上“唐”这个字符。
产生这种乱码情况的简化过程如下:
【GB18030:唐( CC C6)】 —读取为–> 【Windws 1252:ÌÆ(CC C6)】 —转换为–> 【UTF-8:ÌÆ(C3 8C C3 86)】
解决方案是倒推回去,如下:
【UTF-8:ÌÆ(C3 8C C3 86)】—转换为–> 【Windws 1252:ÌÆ(CC C6)】 —读取为–> 【GB18030:唐( CC C6)】
如果还是要使用 UTF-8 编码显示,则如下:
【UTF-8:ÌÆ(C3 8C C3 86)】—转换为–> 【Windws 1252:ÌÆ(CC C6)】 —读取为–> 【GB18030:唐( CC C6)】 —转换为–> 【UTF-8:唐( E5 94 90)】
UltraEdit 编辑器的使用
可使用 UltraEdit 编辑器来查看不同编码下的字符显示,也可以查看字符的二进制数据和进行编码转换。
1、使用不同编码类型来查看
在底部的状态栏可以切换不同编码类型来显示文本。
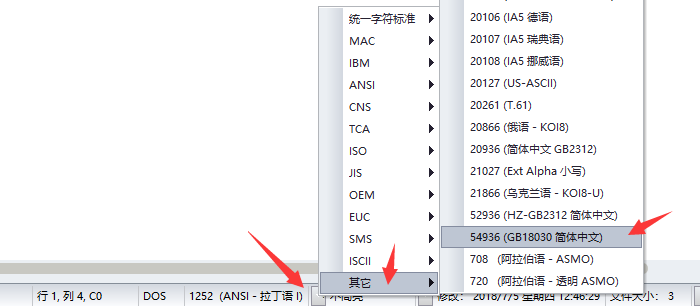
注意:Windws 1252 在 ANSI 分类中,名称为“1252(ANSI拉丁语 I)”
2、查看二进制数据
文档右键菜单中有个“十六进制编辑”,可以查看十六进制数据,快捷键是“CTRL+H”。

注意:在计算机中,二进制数据通常使用十六进制来表示。
3、编码转换
通过菜单“文件 > 转换”来进行编码转换。
注意:Windws 1252 也属于 ASCII 编码,切换选择时要注意。
